
Understanding ControlCore Task Scheduling
Understanding the tasking environment will allow the designer to layout a model that will execute more optimally.
Tasking Kernel
Models often have multiple elements of work that want to execute at the same time, but a system can only execute a finite number of work elements at any given time (one element of work per CPU). It is the responsibility of the operating system (OS), via its tasking kernel, to manage assigning the available CPUs to execute these different sources of work. The priority of execution for a source of work is used by the tasking kernel to make these decisions.
MotoHawk uses a real-time pre-emptive multi-tasking kernel that is housed within ControlCore.
- What is pre-emption?
- Pre-emption refers to the act of a higher priority thread interrupting the execution of a lower priority thread, with the intent of resuming the execution of the lower priority thread at a later time.
- What is Multi-tasking?
- Multi-tasking is referring to systems that use multiple threads to execute work, which allows for priorities and separation of logic.
- What is a task?
-
A task is a thread of execution that can be made to wait for a software defined event to occur. A task that is waiting is not competing for
execution on a CPU and thus yields its execution, which allows a lower priority task that does want to execute to win execution. A
task has its own stack and maintains its own CPU state (also known as an execution context). A task is completely independent from another
task so far as a CPU is concerned. Thus a module that supported dual CPUs could execute one task on one CPU whilst another executed on the
other CPU.
From MotoHawk's perspective a task can be thought of as a container for executing work (linear sequence of CPU instructions) at a defined priority. In essence a MotoHawk task is waiting for execution events (triggers) to occur. When one of those triggers occurs the task becomes readied and competes for execution. If it is the highest priority ready task then it wins execution, which will allow that work to execute.
-
A task is a thread of execution that can be made to wait for a software defined event to occur. A task that is waiting is not competing for
execution on a CPU and thus yields its execution, which allows a lower priority task that does want to execute to win execution. A
task has its own stack and maintains its own CPU state (also known as an execution context). A task is completely independent from another
task so far as a CPU is concerned. Thus a module that supported dual CPUs could execute one task on one CPU whilst another executed on the
other CPU.
- What is an interrupt?
- An interrupt refers to a processor event that is generally triggered by external hardware (Real-Time Interrupt RTI, Angle Event, Communication Event, etc...). Interrupts are a thread of execution and have their own priorities. They can therefore be pre-empted by other interrupts of higher priority. Interrupts always have more priority than a task and thus will always pre-empt tasks (see Interrupt Threads).
Threads of Execution and the Context Switch
Both tasks and interrupts are threads of execution. A context switch defines the process where one thread of execution replaces the currently executing thread on a CPU. This replacement may occur because a thread needs to pre-empt another (because its priority is deemed to be higher than the currently executing thread) or because the currently executing thread wants to yield its execution (it does not want to execute anymore). The following example illustrates the context switch.
Consider that we have two threads, A and B. Each consists of an independent stack and CPU state (state of registers, instruction or program counter, etc...) that are operating on a module with a single CPU. Each thread executes its own linear sequence of instructions, which are determined by the logic under MotoHawk triggers (amongst other things). When the CPU needs to begin executing work from another thread (say B) it performs a context switch where the CPU state of the current thread (A) is saved and the CPU state for the new thread to execute (B) is restored. When a higher priority thread pre-empts a lower priority thread, the lower priority thread's state is saved and the higher priority thread's state is restored and it takes over execution. When the lower priority thread is given back the CPU, it simply restores it's state and continues executing from where it left off.
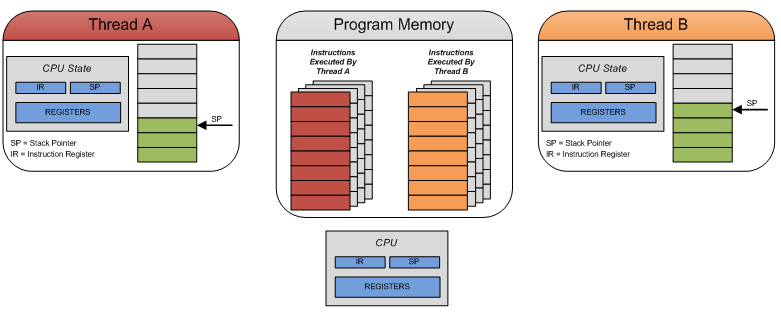
Please note this diagram is not comprehensive and only illustrates a few core CPU components. Also note that "linear sequence of instructions" does not necessarily mean that the instructions are sequentially layed out one after the other in memory, but simply that the next instruction to execute can be determined from the previous instruction.
Default Tasks and Priority
MotoHawk supports a number of default tasks that are configured by the Target Definition block and its Use Advanced Target OS Configuration option hasn't been checked. The default tasks are listed below from highest to lowest priority:
- Interrupt Threads
- Interrupts have more execution priority than tasks and thus will always pre-empt the execution of a task when they occur. Interrupts service hardware events like the tick timer and angle events used by the scheduler. An interrupt pends if interrupts are disabled at the time that the hardware event occurs and will occur as soon as the interrupts are re-enabled. An interrupt can be lost when multiple interrupts of the same source occur while interrupts are disabled because the hardware only catches that an interrupt source is required, but not how many times it is required. This is one reason why care should be taken to keep the time where interrupts are disabled to a minimum. Note that triggering custom logic from within an interrupt is not possible.
- Application Interrupt Task
- The application interrupt task is next in line for highest priority for which communication events, end of pulse events, and queued work from interrupts are generally handled. Triggering custom logic within this task is currently not possible, but a future version will likely allow the application to control the task where certain triggers execute.
- Shutdown Task
- The SHUTDOWN_EVENT trigger executes in the shutdown task that can be used to trigger custom logic on module shutdown.
- FGND Angle Task (foreground angle-based)
- The foreground angle task is used to execute all logic triggered by a FGND angle-based event (e.g. FGND_TDC_EVENT, FGND_MID_TDC_EVENT, FGND_HIRES, et al). Note that this task won't be created if its Foreground Stack Size (Angle-Based) is zero.
- FGND Time Task (foreground time-based)
- The foreground time task is used to execute all logic triggered by periodic FGND time-based events (e.g. FGND_RTI_PERIODIC, FGND_2XRTI_PERIODIC, et al).
- BGND Task (background time and angle-based)
- The background task is used to execute BGND triggered events, including both time and angle-based triggers (e.g. BGND_BASE_PERIODIC, BGND_TDC_EVENT, ONE_SEC_EVENT, ONE_MINUTE_EVENT, et al).
- Idle Task (free-running or idle time)
- The idle task is used to execute free-running tasks (e.g. calculating stack metrics, custom logic triggered by the IDLE_EVENT trigger, etc...). On a side note, the STARTUP_EVENT trigger also executes in this task, but is triggered before the application opens and before timed events are scheduled.
In addition to the default available tasks, MotoHawk also offers explicit tasks that allow the developer to define their own tasks (effectively create their own threads). MotoHawk modules that make use of the MotoCoder technology can utilize these.
The developer also has the option to utilize the Use Advanced Target OS Configuration option where the developer can take on the full responsibility of OS definition. In this configuration the developer is responsible for defining all of the tasks for the application and has greater control over the Operating System (OS) via definition blocks like the ControlCore OS definition block.
Data Coherency
The tasking kernel's multi-tasking nature means that special consideration needs to be given to models that share data between different threads of execution. Pre-emption can result in unintended data corruption, which is discussed in detail here.
MotoHawk Triggers
A MotoHawk Trigger provides the mechanism to allow work to be assigned to a task for execution. Triggers can be thought of as events. MotoHawk abstracts most of its events (e.g. timer tick, angle event, etc...) through the trigger mechanism. All triggers execute within a task. Again, recall that a task is simply a container used to execute logic defined by triggers. A common misconception of triggers is that faster rate triggers will pre-empt slower rate triggers (e.g. FGND_RTI_PERIODIC pre-empting FGND_10XRTI_PERIODIC), but remember that only tasks pre-empt other tasks and there is no notion of pre-emption of a trigger. The behavior of triggers of differing tasks is illustrated by this example.
You can control which trigger executes first within the task by controlling the trigger's execution order. This is illustrated in the Queuing Trigger Example.
The MotoHawk Trigger block is one example of a trigger within MotoHawk and another is the Common Event Trigger block.
Task Timing Example
Lets consider a simple example as illustrated in the figure below. Each block represents 1ms of "work" or CPU time. We have a total of 4 tasks each executing a single trigger and interrupts. The arrows represent the processor events (interrupts). Let us assume the following:
- The time required to schedule a task and switch contexts is negligible and can be ignored
- An interrupt service routine is triggered on communication events (that can occur at any time) that takes a total of 1 ms to execute on each event (green)
- FGND Time Task with the FGND_RTI_PERIODIC trigger occurring every 5 ms that takes a total of 2 ms to execute (violet)
- FGND Angle Task with the FGND_TDC_EVENT trigger that takes a total of 2 ms to execute (red)
- BGND Task with the BGND_BASE_PERIODIC trigger occurring every 20 ms that takes a total of 4 ms to execute (blue)
- Idle Task or free-running default task (gray)
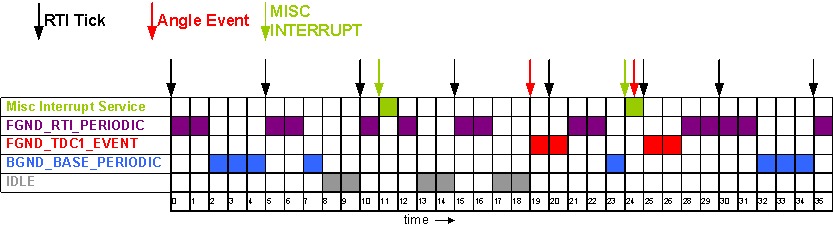
- At t=0, we have an RTI interrupt occur and both the FGND_RTI_PERIODIC and BGND_BASE_PERIODIC triggers get queued by the scheduler. Since the FGND task has higher priority than the BGND task, the FGND wins the CPU and gets scheduled for execution.
- At t=2, the FGND task finishes executing and the task scheduler schedules the BGND task for execution.
- At t=5, we have another RTI interrupt and the task scheduler suspends the BGND task and schedules the FGND task, which takes over the CPU and begins execution.
- At t=7, the FGND task again completes and the BGND task resumes execution until it finishes at t=8. Since no other tasks are queued at t=8, the Idle task executes.
- At t=10, we have another RTI interrupt and FGND_RTI_PERIODIC is ready to be scheduled again. At t=11, a high priority interrupt event occurs, so it pre-empts and suspends the FGND task and takes over the CPU.
- At t=12, it completes and the FGND task resumes execution and so on...
- At t=20, notice we have an RTI interrupt occur; however, the FGND time task is not serviced immediately until the higher priority FGND angle task completes execution. This example shows how the interrupt is not lost, but simply delayed in being serviced because a higher priority task still "owns" the CPU.
- At t=23 there is time for the 20ms BGND_BASE_PERIODIC to execute. At t=24 there is an interrupt and soon after an angle event too. Then at t=25 the RTI occurs again. Once the interrupt at t=24 completes the tasking kernel schedules the highest priority ready task. All of the tasks are ready and so FGND angle wins execution and starts executing. When this yields the next highest priority task executes and so on. Thus BGND does not get to execute again until t=32.
Queing Trigger Example
Now lets better understand triggers and how they execute. Think of a task as a queue that holds triggers, where the trigger event is linked to calling a block (or blocks) of logic (i.e. the logic inside your respective triggered subsystem). If you take a closer look at the MotoHawk Trigger block, you will notice it has a field for an execution order. This priority number does nothing more than control the order of how the trigger gets queued within the task, where lower numbers = higher priority. So for example, lets say we have two subsystems, where one is triggered at FGND_RTI_PERIODIC (base rate of 5 ms) and the other is triggered at FGND_2XRTI_PERIODIC (every 10 ms) and each have 1 ms worth of "work" or CPU time as shown below.
Please note that this is not exactly how triggers execute, but provides a simple visual demonstration where the end result is effectively the same
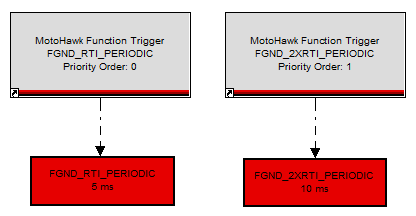
Now let's start at time t=0 and go to t=10ms and visualize the state of the Foreground Time Task "queue".
- At t=0ms, the FGND task "queue" is empty and we have both triggers ready to be scheduled. Since FGND_RTI_PERIODIC trigger has higher execution order than FGND_2XRTI_PERIODIC it gets enqueued first, followed by the FGND_2XRTI_PERIODIC trigger (recall a trigger is just the block (or blocks) of code to call). After the scheduler runs, the CPU can now start executing the trigger logic at the head of the highest priority task queue (in this case, we are just considering 1 task, so the CPU starts executing the logic under the FGND_RTI_PERIODIC).
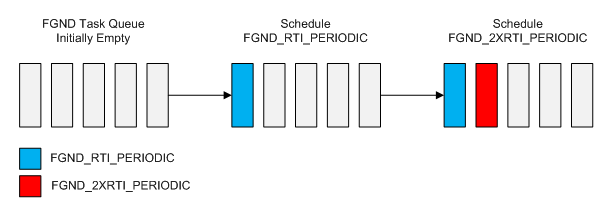
- At t=1ms, assuming no interruptions, the FGND_RTI_PERIODIC triggered logic completes, so the FGND task removes this trigger from the head of the queue and calls the scheduler. The scheduler sees that there is still work to do and begins execution on the FGND_2XRTI_PERIODIC trigger.
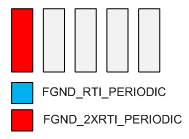
- At t=2ms, assuming no interruptions, the FGND_2XRTI_PERIODIC triggered logic completes, so the FGND task removes this trigger from the head of the queue and again calls the scheduler. The scheduler sees that there is no more work to do at the moment, so defaults to the Idle task and awaits the next interrupt.
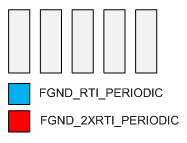
- At t=5ms we receive another base time interrupt and note that only the FGND_RTI_PERIODIC needs to be scheduled. The scheduler schedules this trigger and the CPU begins execution.
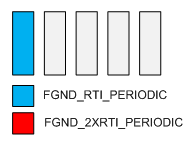
- At t=6ms the FGND_RTI_PERIODIC triggered logic completes execution and the scheduler defaults to the Idle task since there is no other work to execute.
- Finally, at t=10ms, both the FGND_RTI_PERIODIC triggered logic and FGND_2XRTI_PERIODIC are ready to be scheduled for execution again. The scheduler schedules both triggers and again repeats the process.
Again, please note that this is not exactly how things work. The intent of the visual demonstration is to provide the basic concept
Triggers Don't Pre-empt Triggers Example
Another common misunderstanding is triggers that occur more often will pre-empt triggers that occur less often or even asynchronous triggers pre-empt synchronous triggers. Recall though that pre-emption is only related to tasks; whereas triggers associate blocks of logic (triggered subsystems) for a task to execute upon notification from the relative trigger event. Let's consider a real-world example of a 4-stroke 4 cylinder engine running at a constant engine speed of 2000 RPM, where cylinder TDC events are equispaced occurring every 180°. We have a model with logic that is triggered in 4 different subsystems executing on a single core with the following configuration:
| Task | Trigger | Type | Execution Order | Execution Time [ms] |
|---|---|---|---|---|
| 1Foreground Angle | FGND_TDC_EVENT | Asynchronous | 0 | 1 |
| 2Foreground Time | FGND_RTI_PERIODIC | Synchronous (5 ms) | 0 | 2 |
| Foreground Time | FGND_2XRTI_PERIODIC | Synchronous (10 ms) | 1 | 1 |
| 3Background | BGND_BASE_PERIODIC | Synchronous (50 ms) | 0 | 10 |
1,2,3Relative Task Priority (lower number ≡ higher priority)
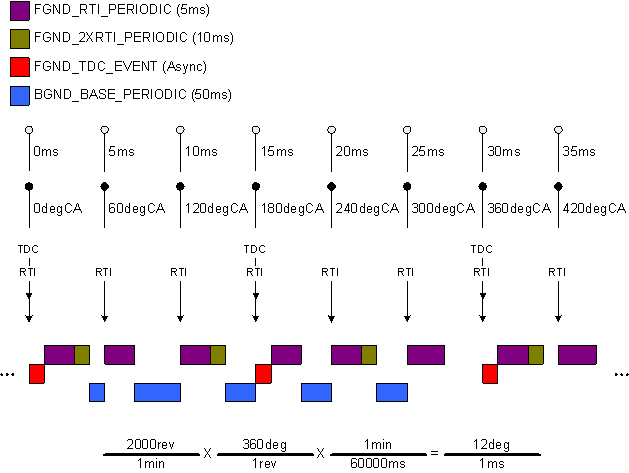
Starting at time=0ms, angle=0°, we have a RTI (real-time interrupt) event associated with the FGND_RTI_PERIODIC, FGND_2XRTI_PERIODIC, and BGND_BASE_PERIODIC time-based triggers as well as a TDC (top-dead center) event associated with the FGND_TDC_EVENT trigger. All triggers are ready to be scheduled; however only one can execute on our single-core system. The FGND_TDC_EVENT trigger executes in the highest priority task (Foreground Angle) and so gets scheduled to execute. After completion, the FGND_RTI_PERIODIC and FGND_2XRTI_PERIODIC are next to execute since the Foreground Time task has higher priority than the Background task; however note that the logic in the FGND_RTI_PERIODIC will execute first, followed by the logic in the FGND_2XRTI_PERIODIC since it has a higher execution order. After the logic in the Foreground Time task completes, the Background task is able to execute until it is pre-empted by the Foreground Time task again at time=5ms.
It should also be noted that triggers of different rates that execute in the same task like FGND_RTI_PERIODIC and FGND_2XRTI_PERIODIC need to complete before the fastest trigger of that group (FGND_RTI_PERIODIC in this case) is triggered again or that event will be late because FGND_RTI_PERIODIC won't pre-empt.
Task Starvation
Overview
Task starvation refers to the phenomena where a task desires to execute, but it is unable to do so because higher priority threads are executing in preference to the starved task. Task starvation is typically seen as a fault condition because it generally isn't normal for CPU utilization to remain at 100% indefinitely and therefore all tasks should be able to execute. Often task starvation is triggered by software malfunction. For example an executing thread that gets stuck in an infinite loop because of an algorithm failure or data corruption would cause task starvation. In this example the threads with an execution priority lower than the "stuck" thread will be "starved" of execution because the higher priority "stuck" thread will continue to execute in preference to them.
Task Starvation Blocks
The Starvation Timer Definition and the Idle Loop Time Get blocks can be used to configure and monitor task starvation. Task Starvation is also an option exposed by the ControlCore OS Definition block.
Periodic Trigger Group Slip Detection (Rate Group Slip Detection)
ControlCore's Periodic Trigger Group Slip Detection will detect whether a time domain periodic trigger group is late to execute and can take action including module reset when such late execution is detected. The premise behind slip detection is to detect when a particular trigger group hasn't met its expected execution period. That is, its expected execution has slipped such that it is considered late. For example, a 5ms trigger group that was not executing within 5ms could represent problematic execution that could be detected by ControlCore's Slip Detection blocks.
Slip Detection can be configured globally or explicitly for each trigger group. Refer to these blocks for further discussion on configuring Slip Detection.
Slip Detection as an Alternate Task Starvation Detection Mechanism
Slip Detection is also able to detect when a periodic trigger group fails to execute at all, which is a symptom of task starvation. Thus installing this protection represents an alternate or additional task starvation protection mechanism. Its use gives a developer more flexibility in detecting and handling rogue execution that can lead to task starvation.
For example, an application that supports a TCP/IP stack may need to set the idle loop time, which is the cornerstone of task starvation detection, to a value that is quite high. The high value is needed because the control may need to spend much of its non-core execution servicing the Ethernet stack, which means that there is little execution time available to execute idle work. If there is little execution available to execute idle then it will take a long time for the idle loop to execute and so a high value is needed to avoid normal execution triggering a task starvation event. An application with a large amount of idle work would also have a higher idle loop time relative to an application with the same CPU utilization, but that had little idle work to do.
An application with a very a high idle loop time will take a long time to detect task starvation. It may not be appropriate for medium priority task that is being starved to wait this long before a problem in the execution is recognized. Slip Detection presents an alternative to detecting such a condition that can be tuned to be more responsive. In this example a long idle loop time could be configured and used to detect problematic execution of the Ethernet stack while Slip Detection could be used to detect problematic execution of the time critical threads without having to wait for the idle loop time based task starvation mechanism.
Custom Application Monitor
Overview
MotoHawk™ supports the Application Monitor Block, but this block has limitations and cannot be used when a target with multiple cores is in use. However, blocks like the Get Task Info allow the application to implement a custom application monitor. The advantage here is the application can directly drive how the application should behave when it suspects a problem.
Stack Monitor Example
This very simple examples illustrates a stack monitor. The Task Info blocks query the task for stack usage (Min Stack Bytes Free) and uses the stack margin (Stack Margin Bytes) to determine whether there is a problem and capture that status in a data store. It then uses the enabled sub-system (which would reside within a separate trigger, but is shown here for convenience) to illustrate how an action could be taken based upon the outcome of the monitor's execution.
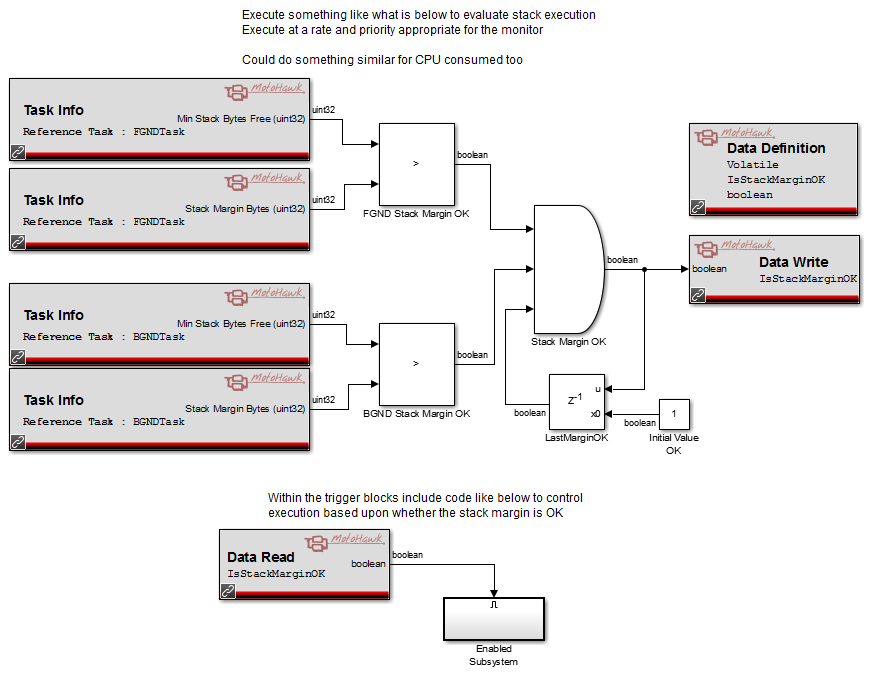
How Often Should a Monitor Execute
Ultimately the rate of a monitor's execution is very application specific. However the model developer should consider data freshness and the type of reactions that will occur when deciding upon the rate of execution.
- Regarding data freshness, consider these examples
- Stack metrics, for example, have the option to be a forced refresh, or to use the data that is refreshed at idle. Checking at a high frequency may not result in new data being used unless the forced refresh is to be used since the newness of the data is dependent upon how much idle is available. The forced refresh consumes CPU bandwidth (the entire stack is scanned to determine the current depth) and does not serve much purpose if CPU idle is high enough to allow that to be calculated when CPU is available.
- CPU% metrics are calculated using a time slice. A new set of metrics are calculated when the time slice expires. The exact time of the time slice depends on the CPU in use, but it is typically targeted to be beyond 100ms. Therefore checking CPU% at a rate faster than the time slice will just check the same data multiple times, without the outcome changing.
- Regarding actions, consider these examples
- CPU% can be used as a kind of runtime validation since there is probably some expectation as to what amount of idle should exist, but the actions that result from such a monitor are to flag a fault without otherwise altering execution behavior. Such an action does not need to execute often.
- CPU% can also be used to actively limit the execution of some application options. For example, perhaps there are prognostics that execute to identify preventative maintenance items. Maybe these don’t need to run all of the time. Conditional execution could be used to drive when these execute based upon available CPU%. Thus the rate that the CPU% is queried is driven by when this algorithm should be switched in or out of the execution stream.
- Stack is definitely a kind of runtime validation test. The intent is to have the application automatically detect when software changes have introduced stack use that encroaches on the margins established to ensure that the application does not run out of stack. If the existing margins are high enough then this can be determined after the fact and so execution does not need to be frequent. Checking more frequently is not going to provide better protection and if the margins are small then likely the execution that encroached on the margin also leads to stack overrun (which can the lead to indeterminate behavior).